상속관계 매핑
자바의 객체, 즉 클래스는 상속을 받을 수 있다. extend를 쓰면 해당 클래스의 메서드나 인스턴스를 쓸 수 있다.
하지만 데이터베이스는 그렇게 되어있지 않다.
말 그대로 관계형 데이터베이스로, 외래키를 이용한 관계들이 얽혀 있어 이를 이용해 객체의 상속을 표현해야 한다.

논리모델을 사진과 같이 구성해, 이를 물리 모델화 시켜야 한다.
물리 모델화 시킨다는 것은 실제 데이터베이스에 들어가는 방식을 설정해야 한다는 것이다.
이 때 크게 3가지 방법이 있는데 조인전력, 단일 테이블 전략, 구현 클래스마다 테이블 전략이 있다.
1. 각각 테이블로 -> 조인 전략

구분자 DTYPE을 메인 테이블에 두고, 구분자를 통해 조인되어 상속을 처리한다.
정규화가 잘 되어있는 편이다.
2. 통합 테이블로 -> 단일 테이블

테이블 하나에 쓰는 부분은 쓰고 안쓰는 부분은 null처리한다.
단순하고, 성능상의 이유로 이렇게 쓰기도 한다.
3. 서브타입 테이블로 -> 구현 클래스마다 테이블 전략

각각의 테이블이 정보를 가지고 있는다.
3 가지 모두 객체 입장에서는 동일하지만, DB 설계의 구조 차이이다.
이제 이를 JPA로 어떻게 표현할지, 그리고 쓰이는 어노테이션이 무엇이 있는지 알아보아야 한다.
주요 어노테이션
@Inheritance(strategy = InheritanceType.XXX) 이를 통해 상속관계 매핑 전략을 설정할 수 있다.
- JOINED : 조인 전략
- SINGLE_TABLE : 단일 테이블 전략
- TABLE_PER_CLASS : 구현 클래스마다 테이블 전략
@DiscriminatorColumn(“이름”) : 슈퍼타입 테이블에 서브타입을 지칭하는 컬럼 명을 바꿀 수 있다.
@DiscriminatorValue(“이름”) : 상속받는 테이블들의 타입명을 바꾸어 줄 수 있다.
이를 이용해 각 전략을 어떻게 사용하는지를 볼 것이다.
조인 전략(가장 정규화됨)
공통 부분의 데이터는 모두 들어가지만, Album, Movie, Book은 모두 다르게 들어가는 정규화된 방법이다. 실무에서 쓰이는 JPA와 가장 유사하다.


이런 식으로 어노테이션을 설정했을 떄,

이런 결과가 나온다.
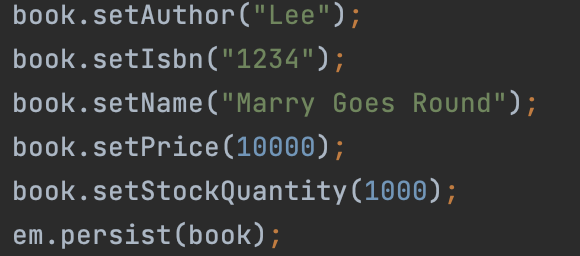
이런 식으로 입력을 넣었을 때 데이터베이스의 저장은
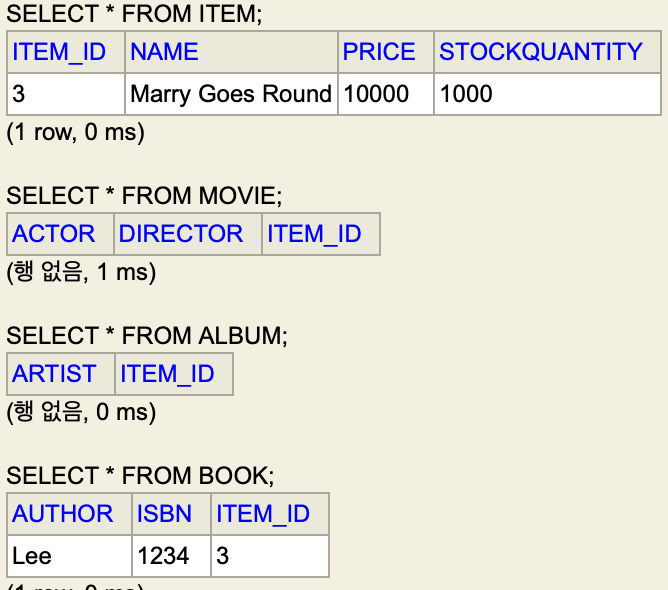
이렇게 나온다.
단일 테이블 전략(가장 단순하다)
테이블 하나에 모든 속성을 넣고 DTYPE로 구분한다.
장점 : 단순하게 사용할 수 있다.
단점 :

이렇게 되어 아까와 같은 입력을 넣어주면

책에 관한 속성을 제외하곤 모두 null을 가지게 된다.
운영상 단일테이블에서는 DTYPE이 없으면 지금 들어가 있는 데이터가 책인지, 영화인지, 음반인지 알 수 없다.
그렇기에 DTYPE을 만들어주어야 하는데, 이 때 Item 클래스에 DiscriminatorColumn 어노테이션을 넣어준다. 그러면

이런식으로 데이터가 어떤 타입인지 알 수 있게 해준다.
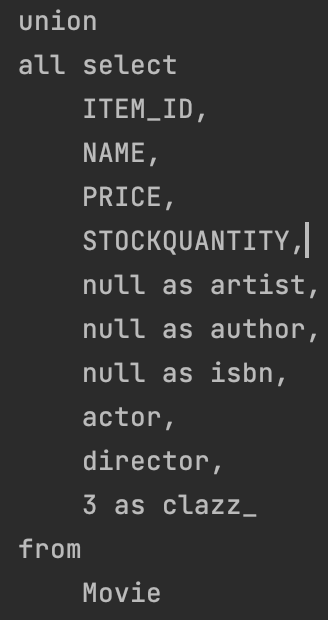
구현 클래스마다 테이블 전략
item의 속성들을 전부 중복되는것을 허용시키면서 각 음반, 영화, 책에 추가시키는 방법이다.
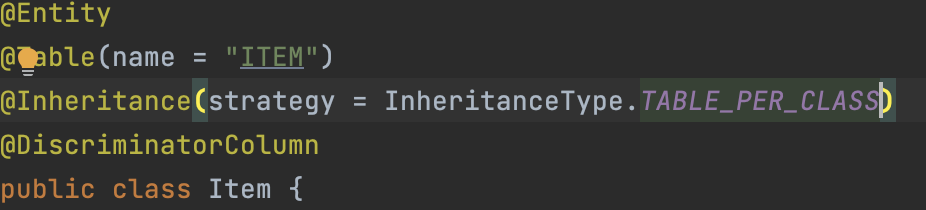
이런 식으로 매핑을 하면

이런식으로 ITEM에 있어야 하는 속성인 가격, 수량, ID, 이름이 BOOK 테이블의 속성들과 같이 Book 테이블에 들어간다.
또한, Item 테이블 자체에 데이터가 있지 않다.
이 때는 DiscriminatorColumn이 필요하지 않다.
문제는 부모 클래스에서 조회시킬 수가 없다는 것이다.
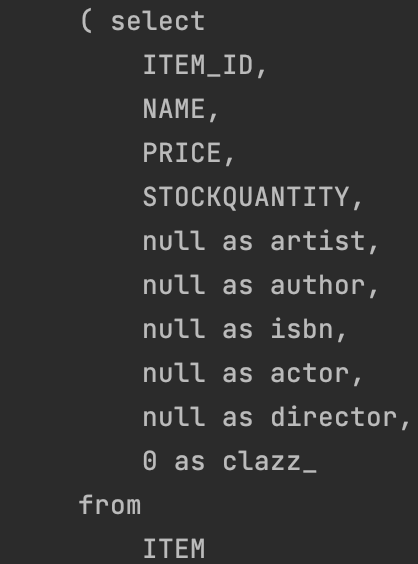


이런 식으로 모든 종류의 상속받는 객체들을 다 뒤져서 Item을 검색한다. 결국 Item 내에서만 찾는게 아니라, 다른 테이블을 다시 다 합쳐서 검색을 한다는 것이다.
조인 전략
장점 : 테이블의 정규화, 외래키 참조 무결성 제약조건 활용 가능(ITEM_ID 서브타입에선 외래키이자 기본키로 받기 때문에 설계를 더욱 깔끔하게 쓸 수 있다. ), 저장공간을 효율적으로 쓴다.
단점 : 조회할 때 join해서 결과를 가져온다. 데이터 저장할 때 insert가 두개 나간다. 단일 테이블보다 복잡하고 성능이 쪼오금 저하된다. (그렇게 크지는 않다)
그래도 저장공간이 효율적이라 조금 더 좋을 수 있다.
상속관계의 기본이라고 생각하고 있자.
단일테이블
장점 : 조인이 필요없어 조회 성능이 빠르다. 쿼리가 단순하다.
단점 : 자식 엔티티의 매핑했지만 쓰지 않는 컬럼들이 전부 null처리된다. 테이블이 커질 수 있고 조회 성능이 그렇기에 떨어질 수 있다.
구현 클래스마다 테이블
관계형 데이터베이스를 쓰지만 관계가 없네?
이게 맞나 싶다.
'스프링 공부 > JPA' 카테고리의 다른 글
| [JPA] 16. 프록시? Proxy? FrogC? 개구리씨? (0) | 2022.12.01 |
|---|---|
| [JPA] 15. 짜잔! 사실 이건 상속관계 매핑은 아닙니다. @MappedSuperclass (0) | 2022.11.29 |
| [JPA] 13. 다대다 매핑(이걸 매핑이라 부를까....?) (0) | 2022.11.03 |
| [JPA] 12. 일대일 매핑(부제 : 짝짜쿵) (0) | 2022.11.03 |
| [JPA] 11. 다대일, 반대로 말하면 일대다 (0) | 2022.11.03 |